文章来源:放心AI网发布时间:2025-04-28 10:53:31
人工智能公司 Anthropic 近日宣布开发了一种名为“体质分类器”的新安全方法,旨在保护语言模型免受恶意操纵。该技术专门针对“通用越狱”——一种试图系统性绕过所有安全措施的输入方式,以防止 AI 模型生成有害内容。
为了验证这一技术的有效性,Anthropic 进行了一项大规模测试。公司招募了183名参与者,在两个月内尝试突破其防御系统。参与者被要求通过输入特定问题,试图让人工智能模型 Claude3.5回答十个禁止的问题。尽管提供了高达15,000美元的奖金和约3,000小时的测试时间,但没有任何参与者能够完全绕过 Anthropic 的安全措施。
从挑战中进步
Anthropic 的早期版本“体质分类器”存在两个主要问题:一是将过多无害请求误判为危险请求,二是需要大量计算资源。经过改进,新版分类器显著降低了误判率,并优化了计算效率。然而,自动测试显示,尽管改进后的系统成功阻止了超过95% 的越狱尝试,但仍需额外23.7% 的计算能力来运行。相比之下,未受保护的 Claude 模型允许86% 的越狱尝试通过。
基于合成数据的训练
“体质分类器”的核心在于使用预定义的规则(称为“宪法”)来区分允许和禁止的内容。系统通过生成多种语言和风格的合成训练示例,训练分类器识别可疑输入。这种方法不仅提高了系统的准确性,还增强了其应对多样化攻击的能力。
尽管取得了显著进展,Anthropic 的研究人员承认,该系统并非完美无缺。它可能无法应对所有类型的通用越狱攻击,且未来可能会出现新的攻击方法。因此,Anthropic 建议将“体质分类器”与其他安全措施结合使用,以提供更全面的保护。
公开测试与未来展望
为进一步测试系统的强度,Anthropic 计划在2025年2月3日至10日期间发布公开演示版本,邀请安全专家尝试破解。测试结果将在后续更新中公布。这一举措不仅展示了 Anthropic 对技术透明度的承诺,也为 AI 安全领域的研究提供了宝贵的数据。
Anthropic 的“体质分类器”标志着 AI 模型安全防护的重要进展。随着 AI 技术的快速发展,如何有效防止模型被滥用已成为行业关注的焦点。Anthropic 的创新为这一挑战提供了新的解决方案,同时也为未来的 AI 安全研究指明了方向。
上一篇: 国家队出手!国家超算互联网平台重磅上线deepseek,免费体验
中国人工智能初创公司 DeepSeek 受到了广泛关注,为了让更多用户方便体验 DeepSeek 的强大功能,国家超算互联网平台宣布上线 DeepSeek Chatbot 可视化界面功能。 用户在这个平台上可以轻松体验 DeepSeek 的
下一篇: AdobeAcrobat推出AI助手,让用户轻松理解合同条款
在日常生活中,许多人都会遇到需要签署合同的情况,而合同的内容往往晦涩难懂。为了帮助用户更好地理解合同条款,Adobe 最近在其 Acrobat 软件中推出了一项新的 “合同智能功能”。这一功能通过 AI 助手的支持,能
相关攻略 更多
最新资讯 更多

好未来MathGPT“出圈”2025财年第三季度净营收达超6亿美元
更新时间:2025-04-29

AI语音独角兽ElevenLabs完成2.5亿美元C轮融资,估值突破30亿
更新时间:2025-04-29
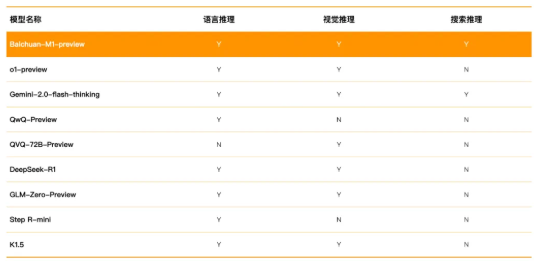
百川智能推出国内首个全场景深度思考医疗大模型,革新医学推理方式
更新时间:2025-04-29

奥特曼加码长寿科技:RetroBiosciences欲筹10亿美元,挑战人类寿命极限
更新时间:2025-04-29

OpenAI新成立的PBC部门估值达300亿美元,微软投资股份尚未确定
更新时间:2025-04-29

扎克伯格表示,2025年底Meta将拥有130万个用于AI的GPU
更新时间:2025-04-29

德勤:企业在推行生成式AI项目上面临规模化挑战
更新时间:2025-04-29

AI基础设施争夺战愈演愈烈:OpenAI与微软的微妙关系
更新时间:2025-04-29

聊天机器人平台CharacterAI以第一修正案为由申请驳回与青少年自杀案的诉讼
更新时间:2025-04-29

Deezer日均上传超万首AI音乐,平台开始检测与标记
更新时间:2025-04-29








